Improve VDSM scalability: sampling
***DRAFT***
Summary
One of the key tasks of VDSM is to monitor the behaviour of the VM running on the hypervisor host. VDSM needs to gather some statistics for each VM, in order to report them to Engine; informally, this gathering task is known as ‘sampling’, a term often used for the sake of brevity. To gather this data, VDSM does not access the OS or to Hypervisor (QEMU) directly, but instead relies to libvirt.
Some of noteworthy statistics are
- physical CPU usage
- virtual/physical CPU mapping
- network I/O
- disk I/O
This task is important, but must be more efficient as possible, in order to save as much hypervisor resource as possible, to be used to run VMs. This page describes the improvements to VDSM and, whenever necessary, to the infrastructure (libvirt) to optimize the sampling.
Owner
- Name: Francesco Romanii (Fromani)
- Email: fromani@redhat.com
Current status
- Target Release: 3.6
- Status: under design and discussion.
- Bugzilla Entry: https://bugzilla.redhat.com/show_bug.cgi?id=1139217
Background
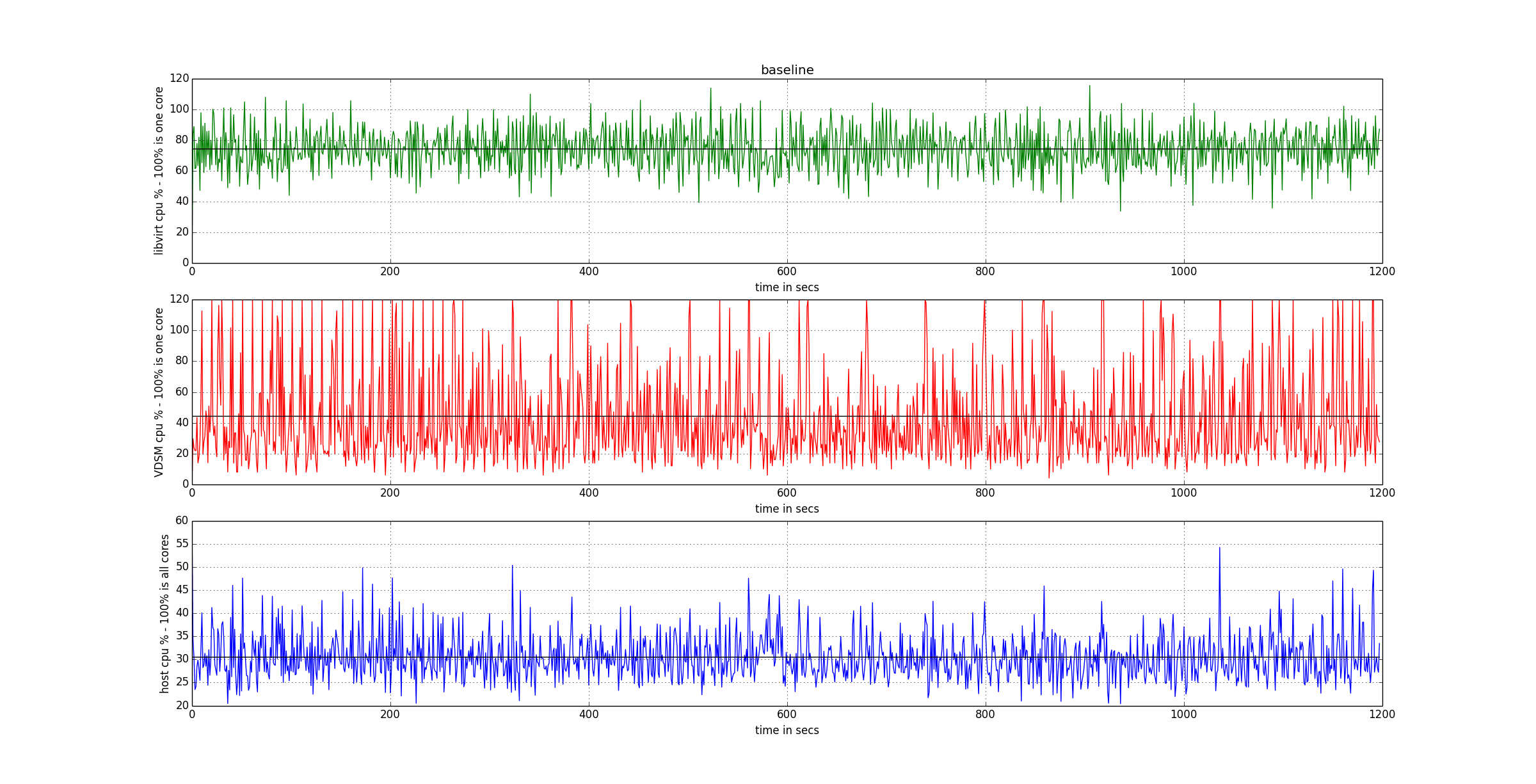
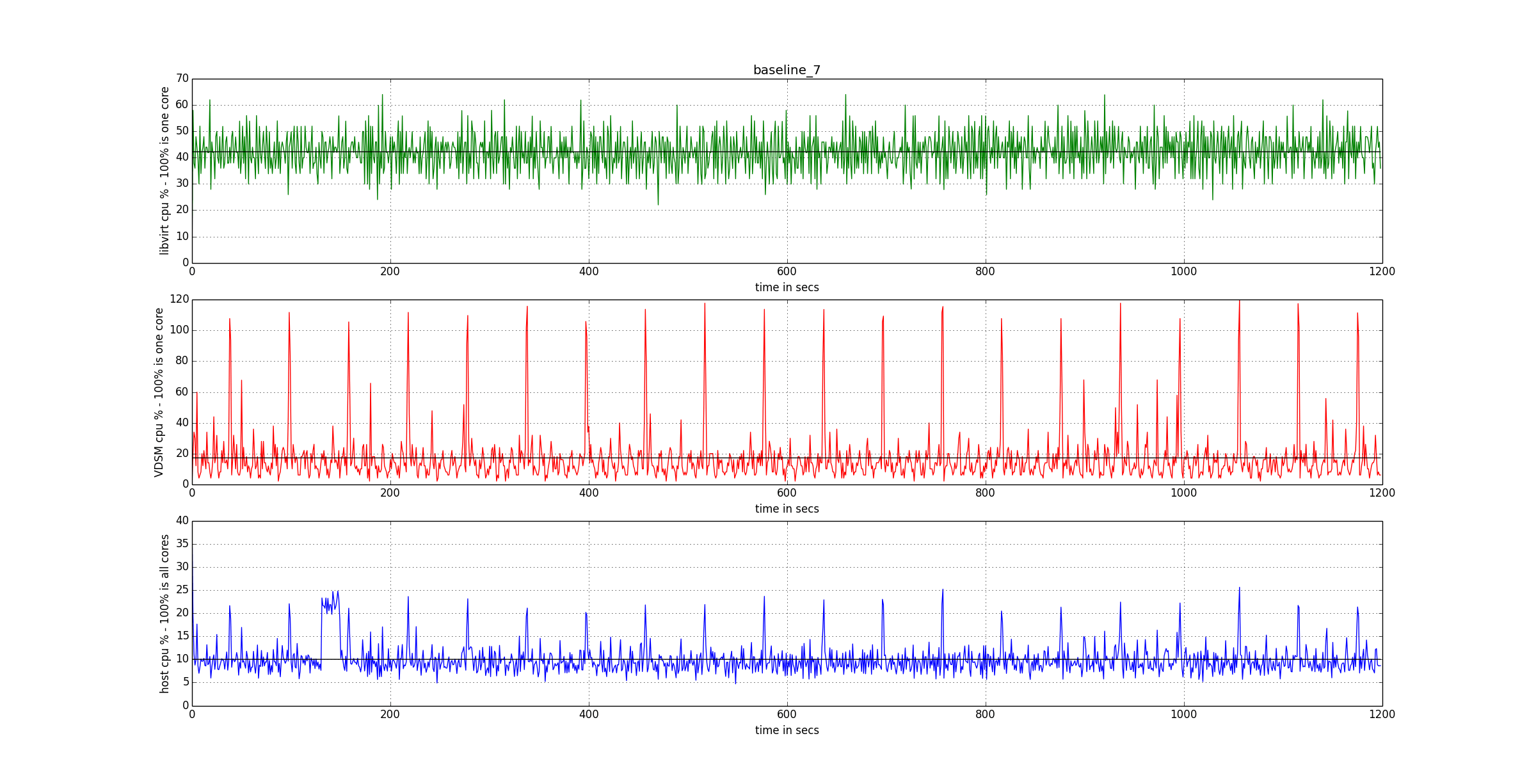
As in VDSM 4.16.x (oVirt 3.5.x), VDSM does sampling using a very fine grained model, which is good for isolation but exposes scalability problems.
- VDSM uses one sampling thread per VM
- VDSM gathers data for each VM using multiple libvirt calls, roughly one for each statistics group, but often more than one.
- MOM (Memory Overcommit Manager), a component used by VDSM, uses one additional thread per VM to do its monitoring.
The suboptimal scalability of this approach is exhacerbated by the fact that VDSM is a python application, and the python default virtual machine has one Global Interpreter Lock (GIL). However, while this design decision is obviously bad for scalability in concurrent CPU-bound tasks, it adds bearable penalty in the concurrent I/O-bound tasks, as is the sampling. Nevertheless, oVirt needs some changes to improve its performances.
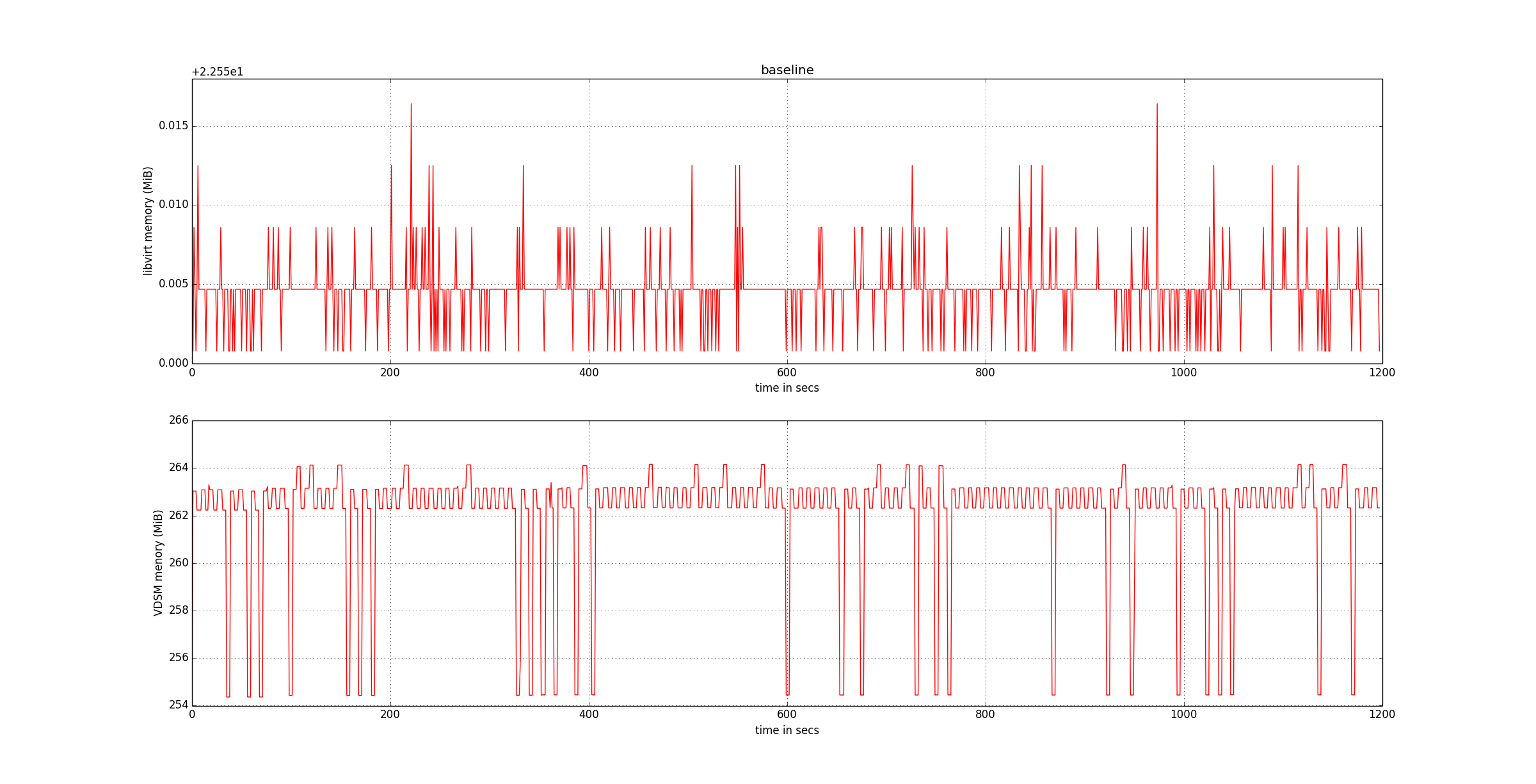
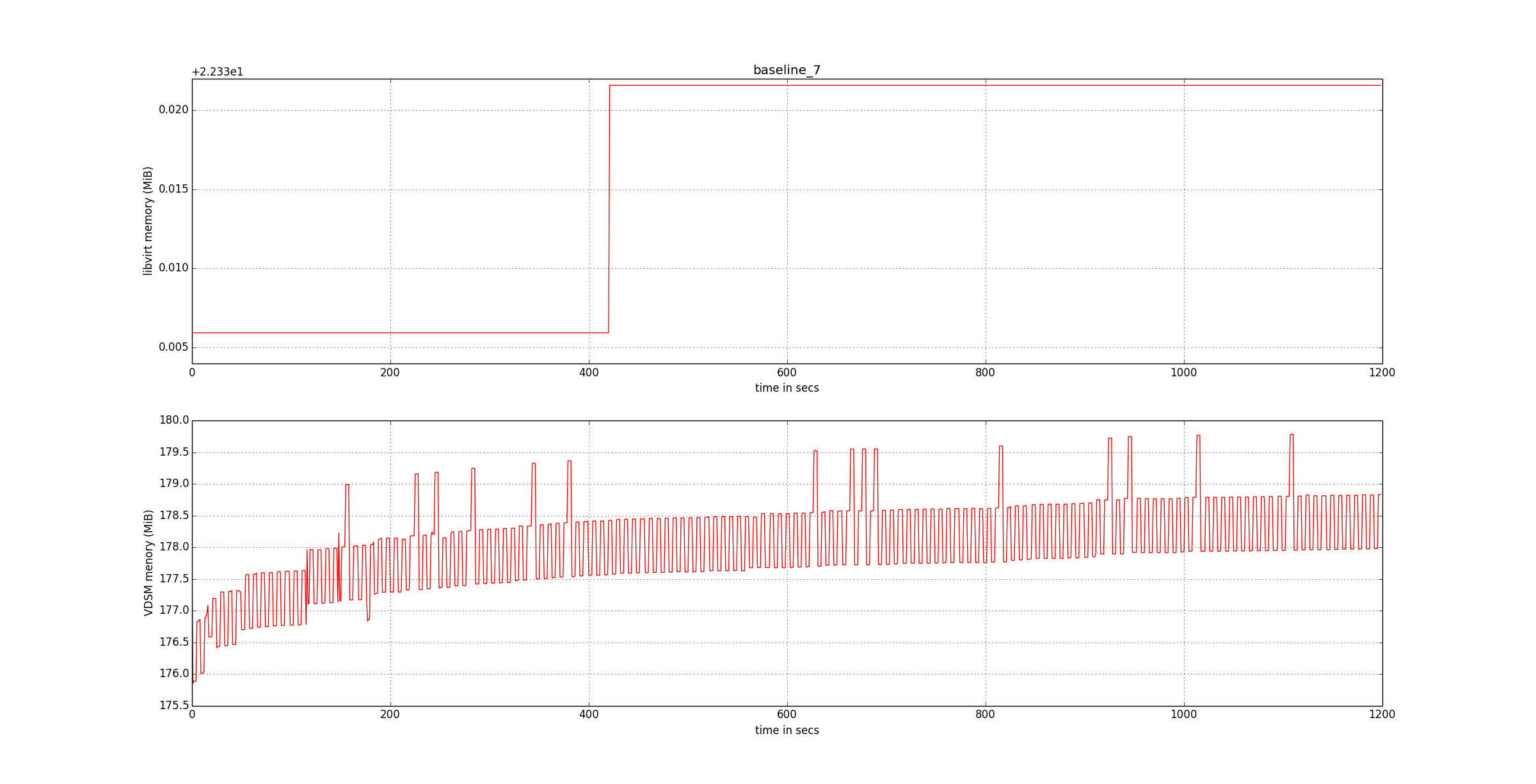
The following graphs provide the baseline to measure the improvements.