Highly Available VMs
What is a highly available VM?
Highly available VMs (HA VMs) are VMs restarted by oVirt automatically whenever they disappear accidentally, such as due to failure of the host running the VM, storage problems or QEMU crash.
How to make a VM highly available
High availability settings are present in the VM editing dialog. Make sure to show Advanced Options there and select High Availability.
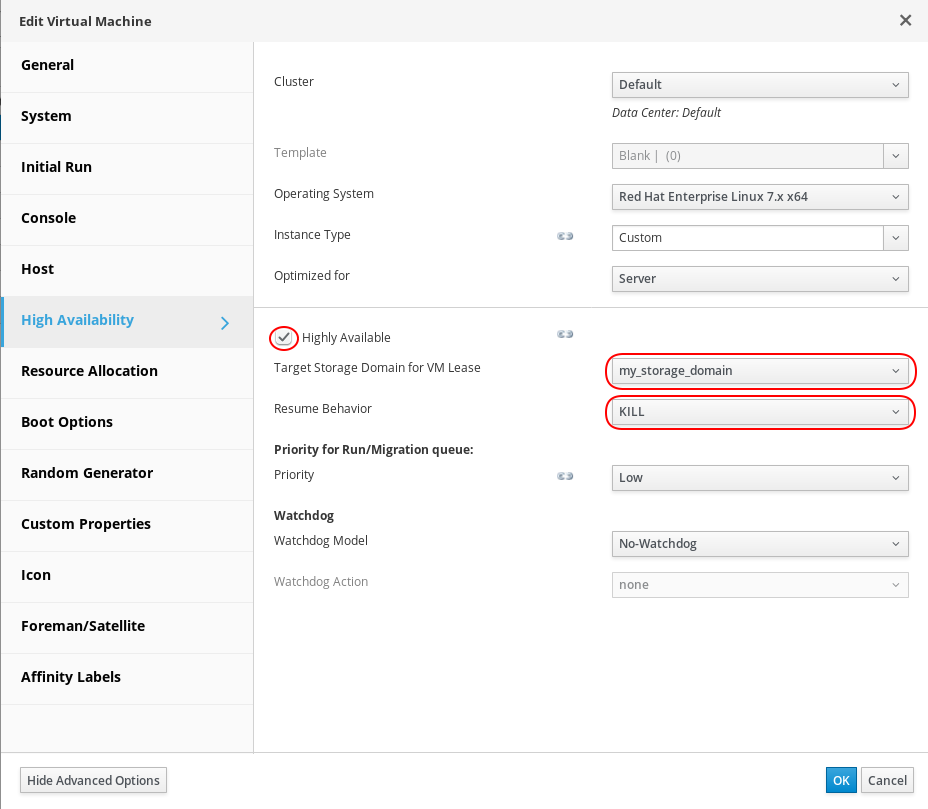
You can see there are several settings there. The primary one is Highly Available check box that must be checked. Some of the additional settings are discussed later in this document.
Are highly available VMs always restarted automatically?
Starting a VM automatically is a bit more complicated than one might initially think. Several conditions must be satisfied in order to start such a VM safely and consistently with user actions.
The very first condition is that oVirt Engine must be fully certain that the VM is not running anywhere at the moment. Failing to satisfy this condition could lead to multiple instances of the VM running concurrently on different hosts, so called split brain situation. oVirt uses safety mechanisms such as sanlock data, VM leases and resume behaviors to prevent split brain. But it’s still important to be aware that if oVirt Engine doesn’t know (under certain setups) for sure that a VM is not already running, it can’t start it automatically elsewhere. For instance, if a host running a VM is unreachable it doesn’t mean that the VM is not happily running there. If corresponding protection mechanisms are not enabled then oVirt Engine may not be able to start the VM elsewhere, despite it is highly available.
VMs manually shut down or powered off from oVirt, from the guest operating system, or by admin-issued host shutdown (which counts as user initiated shutdown) are not restarted automatically. Switching VMs off manually is a user action and oVirt honors it. The user is responsible for starting such a VM again manually.
There may be other reasons preventing start of a highly available VM, such as impossibility to run the VM due to resource constraints at a given moment.
You can watch DevConf.cz talk about highly available VMs and their restarts.
Paused VMs
Besides being running, stopped or unreachable, highly available VMs (as well as other VMs) may also be paused. VMs can be paused for different reasons, for instance:
- A user asks the VM to start paused.
- A VM can be paused for a short while in the final stages of migrations or when making a snapshot with memory. This typically doesn’t harm VM availability.
- When a thin provisioned disk image is getting full and must be enlarged. This is again only temporary situation.
- An I/O error due to inaccessible or broken storage occurs. This is a real problem.
A paused VM can be later switched to another state (typically Running or Down) either automatically (e.g. on migrations) or manually by the user.
Highly available VMs and I/O errors
When a VM attempts to access an unreachable or otherwise broken storage and I/O error occurs, the VM may get paused (unless QEMU hangs in host I/O access or another irregular conditions occur). Then it can’t get running again until the storage problem disappears. The paused VMs can then be handled in different ways by oVirt. Once storage domain is working again, Vdsm goes over all the VMs, highly available or not, on the given host that have been paused due to storage errors (it doesn’t try to resume any other paused VMs). What happens with each of the paused VMs depends on VM resume behavior.
Resume behaviors
VM resume behavior defines how a VM previously paused due to an I/O error is handled once the previously broken storage starts working again. Resume behavior can be selected in High Availability section of VM editing dialog, together with other VM high availability settings.
The following resume behaviors are defined:
AUTO_RESUME: The VM is resumed automatically, as soon as the storage gets working again. This is the simplest scenario – the VM simply pauses for the time of storage problems and then continues running again, without user intervention. It is supposed to be used for non-highly available VMs without special requirements and for highly available VMs when usingKILLbehavior is not desirable for some reason.LEAVE_PAUSED: The VM is never resumed automatically. A user must handle the VM (run it or power it off) manually. This behavior is suitable for VMs that require additional manual interventions after being paused, e.g. some remedy in their guest OS or software running there.KILL: This is similar toAUTO_RESUMEunless the VM is paused for too long. If the storage problem is remedied within a given time interval (80 seconds by default), the VM is automatically resumed. But if the storage problem persists for longer time, the VM is going to be killed sooner or later. This behavior is suitable for highly available VMs, in order to permit them to start on another host, which doesn’t suffer from the storage problem.
Resume behavior can be selected on any VM, not just highly available VMs. But there are special considerations regarding highly available VMs:
- As long as a VM is paused, it may prevent Engine from starting it on another, working, host.
- Or a paused VM may be started on another host and later resumed on the original host, resulting in split brain (the VM runs in multiple instances at the same time).
There is also a special consideration if you use application level high availability in a non-highly available VM. It may be a bad idea to use AUTO_RESUME resume behavior in such a case: If the VM gets paused and the application level high availability handles the situation by running the application elsewhere, confusion may arise if the paused VM starts again. It may be better to use LEAVE_PAUSED or KILL resume behaviors in such setups.
Another special consideration is if an application or other functionality in a highly available VM takes long time to start on boot. Then it may be preferred to leave the VM paused and trying to recover it even if it takes some time rather than trying to restart the VM as soon as possible and then wait for long time before the services inside start working. AUTO_RESUME resume behavior may be preferable to KILL in such a case.
VM leases
VM lease is a feature that guarantees a VM can’t be run in multiple instances at the same time. That guarantee makes restarting highly available VMs safer and thus easier. Split brain is not possible when a VM has been started with a lease and the lease is kept enabled for the VM.
VM leases can be enabled only for highly available VMs, in High Availability section of the VM editing dialog again. Just select Target Storage Domain for VM Lease in the dialog.
Basically, a VM with a lease can start on a given host only after it acquires its lease there. Once the VM stops, gets paused, is killed or its QEMU process crashes, it releases the lease, making it available for starting the VM on another host. VM leases are thoroughly described in a separate document about leases.
To prevent split brain it’s best to use VM leases on highly available VMs. The same also helps restarting highly available VMs on other hosts in case of prolonged storage problems on some of the hosts. Since paused VMs release their leases, the VMs become available for running on other hosts, but can cause trouble when attempting to resume them later on the original host. For that reason KILL is the only possible resume behavior for VMs with leases, which helps destroy the paused VM instance when Engine moves the VM to Unknown status and attempts to start it elsewhere. Of course, KILL behavior means killing the VM under the given conditions, so think about your setup before using it.
Additional notes
VM resume behaviors are available since oVirt 4.2. Older oVirt releases applied AUTO_RESUME behavior on all VMs.
Before oVirt 4.2.2 VMs with KILL behavior used to be killed only once the storage became available, i.e. Vdsm tried to resume the paused VMs. Starting from oVirt 4.2.2 VMs are killed shortly after the timeout expires even when the storage problem persists.
If a VM is attempted to resume while the storage problem persists, it’s going to be paused again sooner or later. That can happen when a user attempts to resume the VM manually or when a Vdsm is tricked into thinking the storage domain status has been changed. The killing timeout resets and starts counting again from the new pause action in such a case.
The killing timeout value can be adjusted in /etc/vdsm/vdsm.conf on the hosts using vm_kill_paused_time option. But don’t do that unless you really know what you are doing!