Most of them are outdated, but provide historical design context.
They are not user documentation and should not be treated as such.
Documentation is available here.
NUMA and Virtual NUMA
Summary
This feature allows enterprise customers to provision large guests for their traditional scale-up enterprise workloads and expect low overhead due to virtualization.
- Query target host’s NUMA topology
- NUMA bindings of guest resources (vCPUs & memory)
- Virtual NUMA topology
You may also refer to the detailed feature page.
Owner
- Name: Jason Liao (JasonLiao), Bruce Shi (BruceShi)
- Email: chuan.liao@hp.com, xiao-lei.shi@hp.com
- IRC: jasonliao, bruceshi @ #ovirt (irc.oftc.net)
Current Status
- Target Release: oVirt 3.5
- Status: design
- Last updated: 25 Mar 2014
Detailed Description
- Query target host’s NUMA topology
The ability to gather a given host’s NUMA topology (the number of NUMA nodes, CPUs, and total memory per node, NUMA node distances), NUMA statistics (free memory per node, CPUs and memory usage per node) from the UI, RESTful API and other APIs. Besides consuming this information for planning and provisioning guests and oVirt scheduler etc. there may be other likely consumers now and in the future.
- NUMA bindings of guest resources (vCPUs & memory)
The ability to optionally specify the bindings for backing memory of a guest (i.e. via numatune with mode set to: strict, preferred, or interleave) along with the vCPU pinning across a desired set of host NUMA nodes from the UI, RESTful API and other APIs. An automatic NUMA balancing feature will be introduced in kernel 3.13. As this technology matures, it should reduce the need for having to specify explicit NUMA bindings.
- Virtual NUMA topology
The ability to specify virtual NUMA nodes for a medium- or large-sized guest from the UI, RESTful API and other APIs. This helps the operating system running in the guest to perform NUMA-aware allocation of data structures and scale better. Automatic NUMA balancing in the guest kernel can take advantage of this, too.
Use Case Diagram
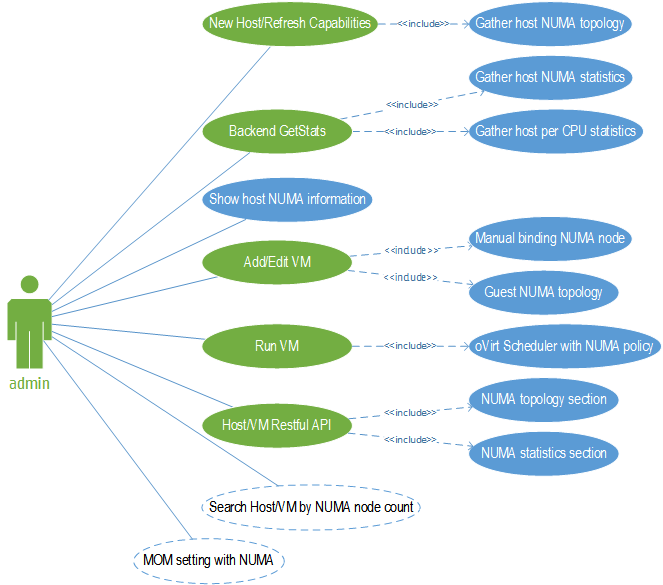
- Color of the use cases
- Green - oVirt features are existed.
- Blue - NUMA related feature.
- Dashed - feature under discussion.
- Use cases in detailed (v1 - current version, v2 - next version)
- When ovirt engine add some host or refresh host capabilities, the
Gather host NUMA topologywill collect the number of NUMA nodes, CPU list and total memory per node, NUMA distances (v2), Automatic NUMA balancing support (v2) from vdsm. - When ovirt engine on timely to do get host statistics, the
Gather host NUMA statisticswill collect free memory per node, CPUs and memory usage per node from vdsm, - The CPUs usage per node is the sum of NUMA node’s CPUs usage depending on
Gather per CPU statistics. It contains CPU’s system, user and idle usage. These data will be used not only by NUMA feature, oVirt scheduler and Report will use them. - By using user interface
Show host NUMA information, administrator will take a loot at host NUMA information, then decide how to configure VM with NUMA aware. - Thus
Manual binding NUMA nodefeature turn on, administrator should know the operation will let the VM lose high availability and live migration as same as CPU pinning feature. Binding NUMA node contain three steps:- Select NUMA tuning mode (strict, preferred or interleave)
- Select NUMA node sets from specified host.
- Check the CPU pinning is suitable for node sets.
- If the VM has the large size (i.e., 40 vCPUs and 512G memory) and cross the NUMA node, the
Guest NUMA topologyis the suggested feature that make the system has better performance. There are two checkpoints:- The sum of Guest NUMA node’s CPUs count must equal to VM total CPU count.
- The sum of Guest NUMA node’s memory size must equal to VM total memory size.
- Follow up
oVirt Scheduler with NUMA policy, these situation should consider:- When
Manual binding NUMA nodeandCPU pinningare configured- If there is enough free memory (each or sum) for binding NUMA nodes to run VM. (v1)
- If there is enough CPU idle (each or sum) for binding NUMA nodes to run VM. (v1)
- If there is enough CPU idle (each or sum) for VM CPU pinning to run VM. (v2)
- When
Guest NUMA topologyis configured- If there is enough free memory per NUMA node to run VM. (v2)
- If there is enough CPU idle per NUMA node to run VM. (v2)
- When
- The
NUMA topology section restful APIis under the Host and VM root section. It contains the list of NUMA nodes, each NUMA node’s CPUs and total memory, node distance (v2), automatic NUMA balancing support (v2). - The
NUMA statistics section restful APIis under the Host root section, it contains each NUMA node’s free memory, CPUs & memory usage. Search Host/VM by NUMA node countandMOM settingwith NUMA are still in discussion and will be published in v2.
- When ovirt engine add some host or refresh host capabilities, the
UI Design Prototype
Work in Progress…
- Host sub tab NUMA information
- Follow CPUs and Memory of each NUMA node information, CPU pinning and manual binding NUMA node on VM is much easier.
- Click Show NUMA distances button will popup panel show distances map.
- Manual binding NUMA node
- Specific host changed on Host tabs will refresh Tuning nodes from the specified host.
- Click Manual Binding NUMA node checkbox, the tuning mode selector and nodes checkboxes will enabled.
- Tuning mode has these values: strict, preferred, interleave
- There is one help box content: Configure wrong CPU pinning against NUMA nodes will take bad performance.
- Guest NUMA topology
- Left node0 CPUs and Memory be blank, system will ignore Guest NUMA topology configuration.
- Click Add and Minus button will increase and decrease NUMA nodes.
- On saving the VM, there are some checks in NUMA topology:
- The sum of every node’s CPUs number should equal to Total Virtual CPUs
- The sum of every node’s Memory number should equal to total Memory Size
Benefit to oVirt
The hypervisor’s default policy is to schedule and run the guest on any available resources on the host. As a result, the resources backing a given guest could end up getting spread out across multiple NUMA nodes and over a period of time may get moved around, leading to poor and unpredictable performance inside the guest. Use the NUMA feature configuration could allow the users to get better performance from their VM’s through using all CPU related memory - including the ones not handled by qemu/kvm. Allows users to get better performance from their VM’s through split virtual NUMA node
Note: Automatic NUMA balancing changes in the Linux kernel (i.e. upstream 3.8 kernel) should help reduce the need for having to explicitly specify this for a guest. But there will still be specific use cases where having this ability in the UI will prove useful.