Most of them are outdated, but provide historical design context.
They are not user documentation and should not be treated as such.
Documentation is available here.
Optaplanner integration with scheduling
The project ovirt-optimizer has been discontinued and it’s no longer maintained. The following section is kept only for reference.
Owner
- Feature Owner: Martin Sivák (msivak)
- Email: msivak@redhat.com
Current status
- Removed in oVirt 4.4. The following content is kept only for reference.
Use Cases
- A virtual machine fails to start due to insufficient resources, and the user wants to know if there is a way to fit the virtual machine
- The user wants to rebalance the cluster to achieve an “optimal” state
Benefit to oVirt
Our users will get hints about how to utilize their hardware better.
Goals
- We want to write a service that takes a snapshot of a cluster (list of hosts and Vms) and computes an optimized Vm to Host assignment solution.
- Optimization will be done on per Cluster basis.
- We intend to implement the service using rules on top of Optaplanner engine.
- The administrator should then be able to use that as a hint to tweak the situation in the cluster to better utilize resources.
- The idea is to have the service free-running in an infinite loop and improve the solution over time while adapting to changes in the cluster.
- The service will be separated from the ovirt-engine to not endanger the datacenter by using too much memory or cpu. It will talk to the engine using an API.
Deployment manual
Two hosts (or virtual machines) are needed - one will host the ovirt-engine and the other will contain the ovirt-optimizer service. Your ovirt-engine must already be installed and configured before you perform the following steps.
There are two repositories you can use:
- latest release - https://copr.fedoraproject.org/coprs/msivak/ovirt-optimizer/
- latest for oVirt 3.6 - https://copr.fedoraproject.org/coprs/msivak/ovirt-optimizer-for-ovirt-3.6/
Five packages are currently available:
ovirt-optimizer-%{version}-%{release}.%{dist}.noarch.rpmovirt-optimizer-ui-%{version}-%{release}.%{dist}.noarch.rpmovirt-optimizer-jboss-%{version}-%{release}.%{dist}.noarch.rpm(or -jboss7 if you install version older than 0.9)ovirt-optimizer-jetty-%{version}-%{release}.%{dist}.noarch.rpmovirt-optimizer-dependencies-%{version}-%{release}.%{dist}.noarch.rpm
There are packages for CentOS 7, CentOS 6 and Fedora 21 and above.
The jboss sub-package supports oVirt’s distribution of Wildfly (ovirt-engine-wildfly).
The older version shipping with jboss7 supports either JBoss 7 from Fedora or ovirt-engine-jboss-as shipped as part of oVirt.
Installing the ovirt-optimizer machine
- Install the
ovirt-optimizer-jettyorovirt-optimizer-jboss(7) package depending on which application server you want to use. - Execute the ovirt-optimizer-setup tool to make sure the Optaplanner library is properly installed (only needed for versions 0.9 and up)
- Edit the
/etc/ovirt-optimizer/ovirt-optimizer.propertiesfile and set the address of your ovirt-engine instance and the credentials for the REST API. - Set up a reverse proxy (nginx or apache) with SSL certificates (see the README file for details)
- Check if the firewall allows external access to the port where your proxy serves the content (443/tcp for SSL enabled optimizer).
- If you performed a fresh installation of Jetty on Fedora 19, you must remove the demonstration configuration file for Jetty to start -
/usr/share/jetty/start.d/900-demo.ini - Start the optimizer -
service ovirt-optimizer-jboss startorsystemctl start ovirt-optimizer-jboss. (Versions 0.8 and older do not have proper service files, but everything works if you start the application server using their scripts -systemctl start jboss-asor/usr/share/java/jetty/bin/jetty.shfor example). - Check the logs in
/var/log/ovirt-optimizer/jbossor in the Jetty log directory and you should see that ovirt-optimizer detected some cluster(s) and tried to compute a solution.
Installing the UI
- Switch to your ovirt-engine machine.
- Install the
ovirt-optimizer-uipackage. - Configure the user interface plug-in by updating
/etc/ovirt-engine/ui-plugins/ovirt-optimizer-config.json- you must put the address and port of the ovirt-optimizer service there. - Restart the ovirt-engine service and reload the Administration Portal.
- Log in to the Administration Portal, navigate to the main Cluster tab and select a cluster. You will now see the oVirt Optimizer subtab in the lower half of the page.
- When you switch to the subtab, it should load some data (might take couple of seconds).
Present Features
- Each cluster has a new subtab - Optimizer results - that shows the proposed optimized solution (both the final state and the steps to get there) and makes it possible to start a migration by clicking the relevant buttons.
- Each virtual machine has two new elements in their context menu - Optimize start and Cancel start optimization. These elements are designed to be used with stopped virtual machines (status Down) and tell the optimizer to identify a solution when the selected virtual machine are started. The cancel menu item cancels this request. You can select multiple virtual machines this way. Sadly, there is no indication in the user interface of the currently optimized virtual machines. However, the result subtab provides a list of virtual machines that are supposed to be started together with the solution details.
- The solution should obey the cluster policy to some extent -
OptimalForEvenDistribution,OptimalForEvenGuestDistributionandOptimalForPowerSavingwill be computed using the memory assignments though (the engine uses CPU load)
Missing Features
- Some hard constraint rules are missing so the solution might not be applicable because of the current scheduling policy.
- Balancing check is missing so the engine might decide to touch the cluster in the middle of your optimization steps - you can disable automatic balancing in the scheduling policy to prevent this.
- No CPU load based rules, the optimizer tries to use the hosts’ memory in an even way (engine uses CPU load in the balanced rule).
Known issues
Data refresh failed: undefined
Check your Firefox (or other browser) version. There is a chance that your browser is new enough and enforces mixed content security rules. That blocks the request to get results from the optimizer. See https://developer.mozilla.org/en-US/docs/Security/MixedContent for details.
You can work around this in Firefox by going to about:config page and setting security.mixed_content.block_active_content to false.
java.lang.OutOfMemoryError
Please check the amount of memory available to the application server.
Jboss is configured in /usr/share/jbossas/bin/standalone.conf (or the respective file in /usr/share/ovirt-engine-jboss-as) and look for the -Xmx option in JAVA_OPTS.
Example:
JAVA_OPTS="-Xms2048m -Xmx8192m -XX:MaxPermSize=256m -Djava.net.preferIPv4Stack=true"
Detailed Description - Internals
This feature will allow the user to get a solution to his scheduling needs. Computing the solution might take a long time so an Optaplanner based service will run outside of the engine and will apply a set of rules to the current cluster’s situation to get an optimized VM to Host assignments.
Getting the cluster situation to Optaplanner
This will be based on REST API after the missing entities for Cluster policy are implemented. In the worst case we might consider to utilize direct database access to get missing data.
The following information is needed:
- List of hosts in the cluster with information about provided resources
- List of all VMs running in the cluster with information about required resources (probably without statistics data for now)
- The currently selected cluster policy is needed together with the custom parameters
- The configuration of the cluster policy - list of filters, weights and coefficients
The ideal situation would be if it was possible to get the described data in an atomic snapshot way. Which means that all the data will be valid at one single exactly defined moment in time.
The Optaplanner service will use Java SDK to get the data and the idea is to get the data once and then (cache and) reuse them during the whole optimization run.
Representing the solution in Optaplanner
Optaplanner requires at least two java classes to be implemented:
- Solution description – a set of all VMs with assigned Hosts.
- Mutable entity for the optimization algorithm to update – the VM itself, the mutable field is the Host assignment
The VM and Host classes can be represented in couple of ways:
- SDK’s Host and VM classes
- Engine internal Vds and Vm classes
The selected representation will depend on the way our Optaplanner service will define the rules for the optimization algorithm (see the next sections).
Reporting the result of optimization
The result will be presented using an UI plugin in the engine’s webadmin. That way the user will have comfortable access to the results from a UI he is used to. Also the authentication and access management to REST will be provided by the webadmin. The disadvantage is that the UI plugin will have to use some kind of new protocol (REST, plain HTTP, …) to talk to the Optaplanner service. Also the UI plugin will have to authenticate to the Optaplanner service, but we are probably not implementing that in the tech preview phase.
There is also a question of how to represent the solution:
- The first prototype will just show a table (graph, image) of the “optimal” VM to Host assignments in a dialog window
- in the future we might be even able to tell the user the order of steps he should perform (migrate A to B…) to reach the state we are showing him
Rules to select the optimal solution (high level overview)
All optimization tasks need to know how does a possible solution look like and how to select the best one. The main task we are trying to accomplish is:
- consolidate the free resources – It should do a defragmentation of free memory or spare cpu cycles so more or big VMs can be started. The extreme case is our Power Saving policy as its side-effect is that a lot of hosts end up totally free of VMs. But we do not want to load the hosts that much. The actual rules that will describe this are yet to be determined, but we are currently looking into using only the hard constraints (filters) of the currently selected cluster policy.
There are two situations that should be avoided in the computed solution:
- Unstable cluster – what I mean here is that once the user performs the changes to get the cluster to the “optimal” state, the engine’s internal balancing kicks in and rearranges the cluster differently. It would mean that the output of the optimization algorithm was not as smart as we wanted it to be. This might be mitigated a bit by using the result of balancer as part of the scoring mechanism.
- Impossible solution – if the user gets a solution from the optimization algorithm and then finds out that the cluster policy prevents him from reaching it, we will have an issue that the theoretical solution can be useless to the user. We will probably start by telling the user to disable load balancing while he is trying to reach “a better” state.
In the case where no solution can be found (for example to the start VM case) we should inform the user that there is no solution with the current cluster policy rules, but that solution to the optimization can still be found if the rules are relaxed a bit.
It is my opinion that the cluster policy rules reflect the actual user’s requirements and we should obey them and make sure all solutions are valid in that context.
Future enhancements
We need to keep improving the Policy unit to DRL rules match.
Implementation details
We implemented the rules using the Drools’ DRL language.
This approach required that we copy the logic from our Java code to drools rules as exactly as possible. Any difference might have caused the found solution to not be applicable to the actual cluster. The rules contain UUID checks so we can relate them to the currently allowed PolicyUnits.
Advantages:
- Users might already be using Drools for other business logic purposes
- Better performance
- Uses Java SDK classes directly
- Smaller footprint (does not need the ovirt-engine)
Disadvantages:
- Code duplication – the rules have to be kept in sync with engine’s PolicyUnits or we might compromise the fitness of computed solutions
Examples and demostrations
Example of suboptimal balancing as a result of starting VMs one by one
This example uses just a single resource and evenly balanced policy. At the end all the Hosts should be providing the same amount of that resource to the VMs.
There are 4 VMs and 2 hosts:
- Vm_A: 330MB of memory
- Vm_B: 330MB of memory
- Vm_C: 330MB of memory
- Vm_D: 1000MB of memory
Now lets investigate what happens when the starting order is A,B,C,D:




And as a second case D, C, B, A:




Notice that the second case is much better with regards to equal balancing, but has less free space for a new VM. It is necessary to determine the priorities without guessing to select the proper solution according to user’s needs.
Screenshots of the UI plugin in version 0.3
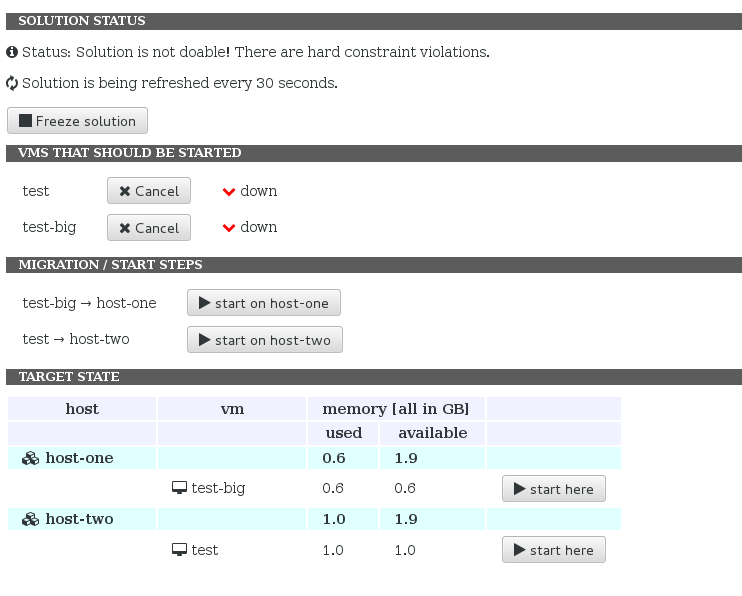
When there is nothing that needs to be done in the cluster, you will see something similar to this:

After a VM start is requested, the display will reflect that a VM is being scheduled and give you the chance to start the VM on the computed dectination host:
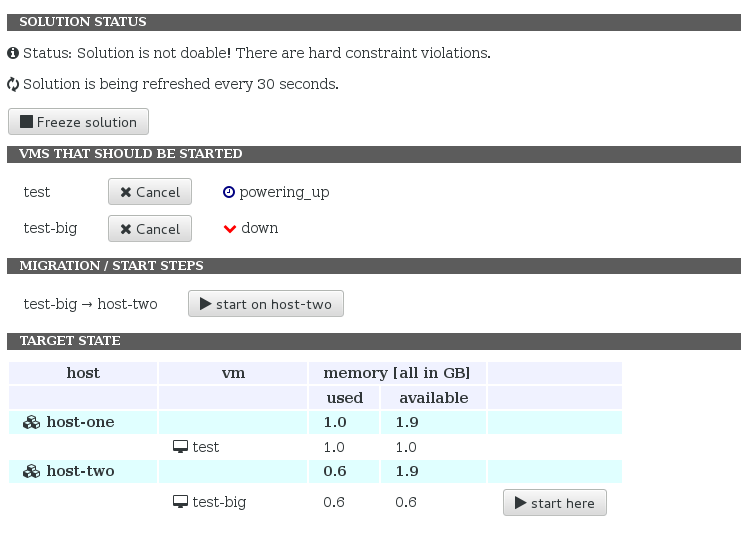
Starting the VM changes the status (the icon is missing here, but will be present in the version):
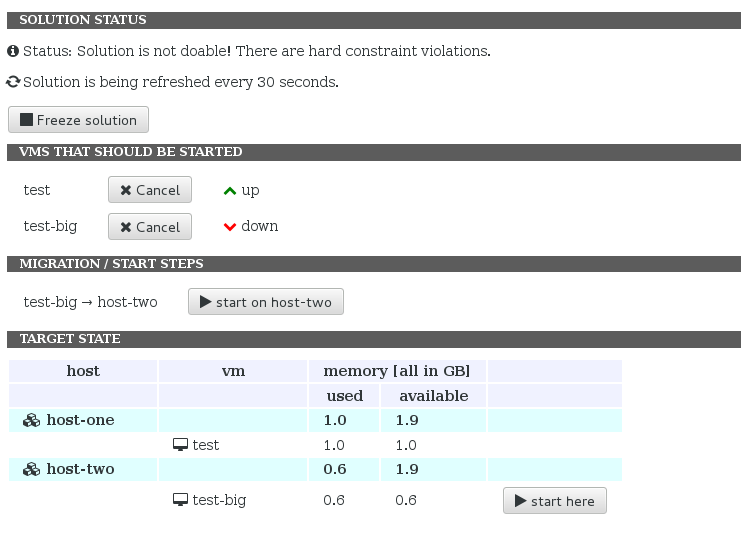
VM started successfully. It is still visible here, but will disappear from the list after the next result refresh (the optimizer needs some time to update the solution with the new state):
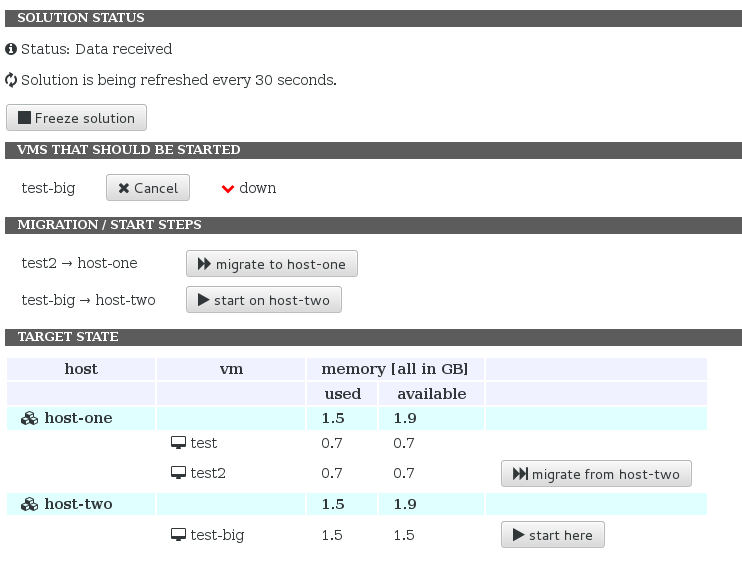
Compute a “complicated” start VM solution
This demonstration shows a situation where the starting VM does not directly fit to any host. The first picture shows that all hosts are partially occupied and there is no host with 1.5 GB of free RAM that is needed for the VM we are about to start.

When optimizer kicks in the following solution is found. One of the small VMs is migrated and the freed space is used to start the big VM.