Mass VMs Run
Summary
This page summarizes an effort which is made to improve the scalability of the process of running VMs.
We might need to start high number of VMs in about the same time in the following scenarios:
-
Host that ran high numbers of HA VMs went down, so all those HA VMs should be auto started.
-
The user asked to run high number of VMs, either by the UI or by scripts.
In case the environment contains few hosts, or in the extreme case one host which is capable to run all those VMs, the slowness of running high number of VMs in parallel is more noticable. As such kind of environments become more and more common, this issue becomes more serious.
We know about multiple processes in the system which can be more efficient, both in the engine and in VDSM, and we believe that together they will make a significant improvement on the process of running high number of VMs in parallel. As It is not feasible to do all of them at once, we’ll make them incrementally and monitor their effect.
Owner
- Name: Arik Hadas (Arik)
- Email: ahadas@redhat.com
Current status
- Status: Design
Stage 1
Intoroducing a central place in the engine, VmsRunner, which will be responsible to run VMs. All the requests to run VM [1] (except reruns) will be made through this place.
The benefits of having a central place which is reponsible for running VMs:
- Run VM requests which came around the same time can be prioritiezed [2] [3]
- VMs that should be run can be aggregated and then scheduled in a bulk
- Run VM commands which are targeted to the same host can be grouped together and be sent in one message to vdsm
- The history of VMs that were run on each host recently can be easily saved in memory and be accessed when inspecting further run requests
The VmsRunner will be a quartz job, similar to AutoStartVmsRunner which was recently introduced for running highly available VMs that went down unexpectedly: when request to run VM come, the VM will be added to internal data-structure in VmsRunner. When the VmsRunner job wake up, it will go over all the VMs in the internal data-structure and try to run them. The time interval for the job will be configurable. The api will provide a way to run the VM in regular/run once mode and as internal/external command.
There are two special cases: 1. In AttachUserToVmFromPoolAndRunCommand, instead of firing the run vm command right after the attaching the user, the VM will be placed in the VmsRunner. That means that we’ll need to ensure that if the run fails, 2. UI
Caching the RunVmCommands and sending them in a bulk to vdsm is expected to reduce the time spent on waiting for the synchronized call to the create verb in vdsm to end. A diagram that demonstrates the current flow:
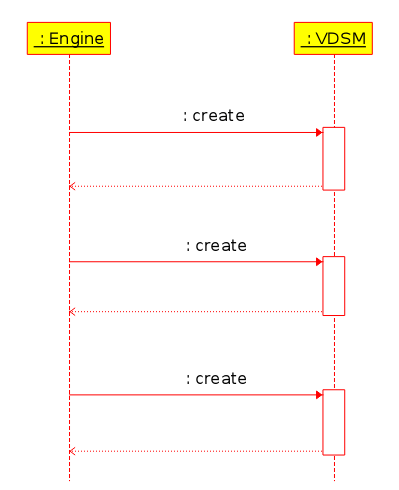
As we can see, the engine call the ‘create’ verb, which in turn start vm creation thread in vdsm and only then the call ends and the engine continue to the next RunVmCommand that invokes the next ‘create’ verb. It should not be long time to end the synchronous call though (~2 sec in our tests), but when it comes to high number of calls it accumulated and thus noticable. Assuming the destination host is capable to run multiple VMs in parallel (it depends on its number of cores), we can reduce the overhead by combining the different calls to one call:
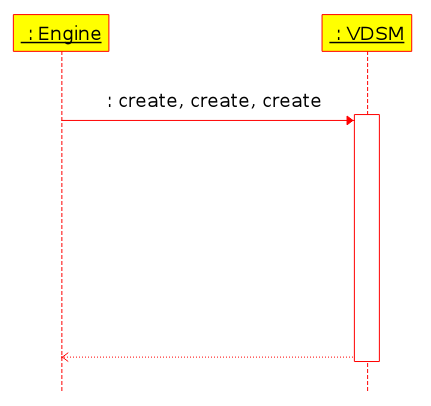
The expected benefits of such change are:
- Reduce the time needed to set up connections between the engine and VDSM by reducing the number of connection establishments to one
- Reduce the time needed to encode & decode the XMLs describing the VMs by encoding all the information at once
- This design will make it possible to invoke the operation against each host in a different thread which should accelerate the process of running VMs on more than one host
- This design is a step forward for being ready to call the scheduler for scheduling multiple VMs in a bulk
There’s a trade-off when it comes to declare for how long should we aggregate the run VM request: on the one hand, setting it to too short period mean that we may end up with too many calls to host as we had before. On the other hand, setting it to long period would mean that the VMs could maybe be run faster by sending them separately.
Stage 2
draft: thread per host draft: update hibernation volumes without VDS lock draft: don’t execute all can do actions for HA that is being run immediatly after it went down
Future changes
- Change scheduler to schedule multiple VMs together instead of each one separately.
- Improve the VM statistics mechanism to work in a bulk
[1] The places where run vm requests come from: 1. The monitoring (VdsUpdateRuntimeInfo) automatically starts highly available VMs that went down 2. The monitoring trigger rerun for failed migration/run commands 3. The prestarted VMs monitoring job 4. REST api 5. UI
[2] The priority of running VMs should probably be: 1. run highly available VMs that went down 2. rerun attempts 3. the prioritization made by RunVMActionRunner
[3] Currently we prioritize only bulk of run requests that comes from the UI (in RunVMActionRunner), prioritize them in the VmsRunner will be more general.