Most of them are outdated, but provide historical design context.
They are not user documentation and should not be treated as such.
Documentation is available here.
HA VM reservation
HA VM reservation for host failover
Summary
The HA VM reservation feature ensure the safety of HA VMs in case of host failover, without negatively impacting performance.
Owner
- Name: Kobi Ianku (kianku)
- Name: Scott Herold (sherold), Email: sherold@redhat.com
Current status
- Target Release: 3.4
- Status: design
Detailed Description
oVirt Manager has the capability to flag individual VMs for High Availability, meaning that in the event of a host failure, these VMs will be rebooted on an alternate hypervisor host. Today, it is possible that the resultant utilization of a cluster during a host failure may either not allow or could cause a notable performance degradation when HA VMs are rebooted. HA VM Reservations will serve as a mechanism to ensure appropriate capacity exists within a cluster for HA VMs in the event the host they currently resides on fails unexpectedly.
Terminology n+1 failover - A scenario in which VMs recover from a single-host failure within a cluster n+x failover - A scenario in which VMs recover from a multi-host failure within a cluster
For the first iteration of HA VM Reservations, oVirt shall consider a single host failure (n+1). Scenarios involving multiple host failures (n+x) shall be deferred to a future release due to the complexity incurred from the individual VM HA setting approach (vs. Cluster Level HA Policy).
Concept The HA VM reservation mechanism will be implemented in two phases: for the first phase the oVirt manager will be enhanced with monitoring capabilities. oVirt will continuously monitor the clusters in the system, for each Cluster the system will analyze its hosts, determining if the HA VMs on that host can survive the failover of that host by migrating to another host. In the event that an HA VM cannot migrate upon a Host failure, an Alert will be presented to the end user.
To illustrate: In the following diagram, we note that Hosts 1, 2, and 3 should all be able to failover their HA VMs successfully to alternate hosts within the cluster, whereas there simply isn’t enough available capacity across Host 1, 2, and 3 for the HA VMs in the event that Host 4 fails.

The monitoring procedure logic: split the host into HA VMs and try to find several host that will replace the failover host.
-
A pseudo code for that:
1. for each host x in the cluster do: 2. calculate HA VMs resources -> resourceHA(x,vm(i)) 3. for each host y in the cluster, y<>x do: 4. calculate the host y free resources -> resourceFree(y); 5. for each HA VM v for host x do: 6. while resourceFree(y) >= resourceHA(x,vm(v)) 7. resourceFree(y) = resourceFree(y) - resourceHA(x,vm(v)); 8. mark v as migrated; 9 if all HA VMs are marked as migrated -> ClusterHAStateOK else ClusterHAStateFailed(raise Alert)
Important - because of the complexity of this scheduling problem, we have decided to use a naive approach Second phase of the implementation is to extend the monitoring capabilities to the “Run VM” and “Migration” actions. For migrating a VM the task is relatively simple, because changing a host in the cluster will not change the balance of the cluster. The HA VM reservation state will not change because of a migration action. For running a new HA VM we will need to place it at the most suitable host, for that we will use the scheduling mechanism and add to it a new functionality to take the HA resources taken on each host into account. Basically the Engine will calculate the amount of used HA resources, the host with the lowest usage will get the highest score. More details on this functionality can be found at the detailed design page.
another module that will be enhanced is the balancing mechanism, a new balancing method will be added making sure that HA VMs will be well spread thru the cluster. the balancing mechanism is self triggered run runs in the background, no user action is needed for this method to perform. The balancing method will be based on the existing even-distributed one, the method will add treatment to HA VMs, making sure the HA VMs are more balanced over the cluster.
GUI
Enabling or disabling the HA VM Reservation will be possible via the Cluster new/edit popup.
A sketch of the edit Cluster window:
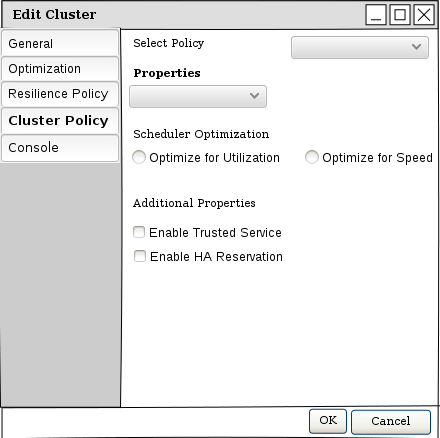
When enabled the weight and balancing methods will kick into action as well as the monitoring task that will trigger an alert to the user when needed.
Detailed Design
Detailed design can be found here HA_VM_reservation_detailedDesign
Benefit to oVirt
Provide assurance to the end user that critical VMs will have access to the required resources in the event of a host failure without negatively impacting the collective performance of existing workloads