Most of them are outdated, but provide historical design context.
They are not user documentation and should not be treated as such.
Documentation is available here.
HA VM reservation detailedDesign
HA VM reservation detailed design for host failover - phase 1
Summary
High level design can be found at Features/HA_VM_reservation
Owner
- Name: Kobi Ianko (kianku)
- Email: kobi@redhat.com
Current status
- Target Release: 3.4
- Status: design
- Last updated: ,
Detailed Description
concepts
The HA VM reservation feature purpose is to inform the end user on scenarios that a failover of a host might cause a performance downgrade. To do that, the oVirt engine will monitor the hosts on each cluster and raise alerts in cases it uncovers such a scenario. The monitoring will be perform:
- As a background task, tracking changes in the VMs that might cause a scenario as described above.
- For each run/migrate command, tracking the changes cause by the command.
measuring the vm resources
For us to begin monitoring the cluster, we need to decide how this monitoring will be performed.
For the weight & balancing functions: The aspects of a VM that are relevant for our monitoring are the amount of HA VMs in host. There is no need to calculate CPU and RAM consumption, this will be handled for us by the other weight functions (evenly distributed, power saving, …).
For the monitoring task: The aspects of a VM that are relevant for our monitoring are the CPU and RAM. Our goal is to determine if other hosts have enough free CPU and RAM resources to take the place of a certain host. When calculating the cpu usage of a VM we will need to take into account the number of cores/threads on the VM and host. The following calculation will return the usage percentage of the VM from the host:
int curVmCpuPercent = vm.getUsageCpuPercent() * vm.getNumOfCpus() / vds.getCpuCores()/*(or Threads)*/);
RAM usage will be simpler:
int curVmMemSize = (int) Math.round(vm.getMemSizeMb() \* (vm.getUsageMemPercent() / 100.0)); /*curVmMemSize is the used Ram in MB by the VM.*/
monitoring background task
Once we know how to calculate the VM resource, we can monitor it, the following pseudo code will show the monitoring strategy. split the host into HA VMs and will try to find several host that will replace the failover host.
- A pseudo code for that:
1. for each host x in the cluster do: 2. calculate HA VMs resources -> resourceHA(x,vm(i)) 3. for each host y in the cluster, y<>x do: 4. calculate the host y free resources -> resourceFree(y); 5. for each HA VM v for host x do: 6. while resourceFree(y) >= resourceHA(x,vm(v)) 7. resourceFree(y) = resourceFree(y) - resourceHA(x,vm(v)); 8. mark v as migrated; 9 if all HA VMs are marked as migrated -> ClusterHAStateOK else ClusterHAStateFailed(raise Alert)
acting on run/migrate actions
This part is a bit more tricky, we would like oVirt to have the capability of not only monitor the current state of the cluster but to actually make an active decision when running/migrating a VM. by selecting the best host to place the VM.
For that we will add a new weight function to the existing one presented in the scheduling feature Features/oVirtScheduler. The existing one combined with the new weight function will present a result for the best host to apply the VM into.
- The scoring method
The scoring method will enable the Ovirt engine to make the best decision to where should the VM run(on which host).
F(VMi) = the amount of HA VM in the host.
- Adding a HA VM
using the already existing mechanism when adding a VM the system do the following:
- filter out non relevant hosts, using the hard constraints filters.
- apply the weight function to scoring the hosts based on the cluster policy.
- apply the HA reservation weight function scoring the hosts taking into account the HA resources taken for each host.
- merge (2) and (3) to a single number representing the score of the host based on the cluster policy and HA resources.
- the host that will score the lowest will be the one to receive the VM.
- Balancing the cluster
using the existing balancing mechanism, we will add a new balance method that will be based on the existing even distribution method, this new method will return a VM to migrate in cases there are too many VMs on a host, with special attention to HA VMs. The method will return a vm and a list of potential hosts to migrate to.
UI
Enabling or disabling the HA VM Reservation will be possible via the Cluster new/edit popup.
A sketch of the edit Cluster window:
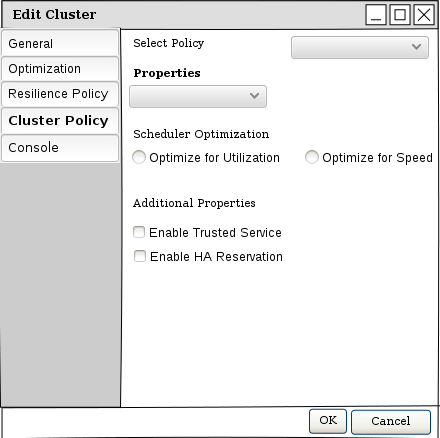
When enabled the weight and balancing methods will kick into action as well as the monitoring task that will trigger an alert to the user when needed.
A second UI change will be at the Alert window, in case the system will recognize the scenario in which a HA VM cannot be migrated after a Host failover without causing a performance downgrade, a new alert will show specifying the problematic cluster and list of problematic Hosts in that cluster.
The message to be presented to the user:
Cluster <ClusterName> failed the HA Reservation check, HA VMs on host(s): <Host1, Host2, ...> will fail to migrate in case of a failover, consider adding resources or shutting down unused VMs.
The new weight function, “optimal for HA Reservation”, was added to all the default cluster policies, to view or edit the policies go to cluster policies
configuration tab in the configure popup windows.
- User configurable settings
At the cluster popup edit window, the user may select his policy for the cluster. when selecting a policy with a HA Reservation weight/balance function, two parameters could be changed by the user:
- overUtilization: a percentage number that represent the over utilization threshold (default is 200%) from the optimal use case. For example in case the optimal HA VMs for a host is 2, and overUtilization is 200, HA VM will not be migrated by the balance method until the host has at least 5 HA VMs (>2*200%).
- scaleDown: a number to reduce by the result of the HA Reservation weight score (default is 1). For example if the score of a host is 90 and scaleDown is 2, then the final score for this host will be 45. This parameter enable the user to reduce the impact the HA Reservation weight function has on the total scoring of the host.
- please note that usually there is no need for the user to change the default setting.
ENGINE
The engine will implement the logic of this feature, it will be responsible for the scoring mechanism shown above, and maintaining the background task of monitoring the state of the clusters. For the monitoring task we will use Quartz to run a job every 5 minutes. the job will implement the pseudo code shown above for the monitoring task.
The quartz task will be configured in the SchedulingManager class, and set to execute every 5 minutes. since it is a singleton class we will schedule the job at the getInstance method.
DB
Since there is no use of persisting the data, because it is relevant for a short period of time, no DB changes are needed. On the other hand the configuration should be persistent. For each Cluster we will save it own ha reservation selection(true or false)
for saving the configuration we will add a new field to the vds_group “ha_reservation” with a default of false.
ha_reservation boolean NOT NULL DEFAULT false
possible values for this field are true/false according to the user selection in the checkbox at the cluster popup window (shown at the UI section).
also we will need to add a new weight and balance functions and assign them to all the default policies:
INSERT INTO policy_units (id, name, is_internal, custom_properties_regex, type, description) VALUES ('7f262d70-6cac-11e3-981f-0800200c9a66', 'OptimalForHaReservation', true, '{
"ScaleDown" : "(100|[1-9]|[1-9][0-9])$"
}', 1, 'Weights hosts according to their HA score regardless of hosted engine');
INSERT INTO policy_units (id, name, is_internal, custom_properties_regex, type, description) VALUES ('93431200-6d7e-11e3-981f-0800200c9a66', 'OptimalForHaReservation', true, '{
"OverUtilization" : "([1-3][0-9][0-9])$"
}', 2, 'balance hosts according to their HA score regardless of hosted engine');
INSERT INTO cluster_policy_units (cluster_policy_id,policy_unit_id,filter_sequence,factor) values ('20d25257-b4bd-4589-92a6-c4c5c5d3fd1a','7f262d70-6cac-11e3-981f-0800200c9a66',0,1);
INSERT INTO cluster_policy_units (cluster_policy_id,policy_unit_id,filter_sequence,factor) values ('5a2b0939-7d46-4b73-a469-e9c2c7fc6a53','7f262d70-6cac-11e3-981f-0800200c9a66',0,1);
INSERT INTO cluster_policy_units (cluster_policy_id,policy_unit_id,filter_sequence,factor) values ('b4ed2332-a7ac-4d5f-9596-99a439cb2812','7f262d70-6cac-11e3-981f-0800200c9a66',0,1);
INSERT INTO cluster_policy_units (cluster_policy_id,policy_unit_id,filter_sequence,factor) values ('20d25257-b4bd-4589-92a6-c4c5c5d3fd1a','93431200-6d7e-11e3-981f-0800200c9a66',0,1);
INSERT INTO cluster_policy_units (cluster_policy_id,policy_unit_id,filter_sequence,factor) values ('5a2b0939-7d46-4b73-a469-e9c2c7fc6a53','93431200-6d7e-11e3-981f-0800200c9a66',0,1);
INSERT INTO cluster_policy_units (cluster_policy_id,policy_unit_id,filter_sequence,factor) values ('b4ed2332-a7ac-4d5f-9596-99a439cb2812','93431200-6d7e-11e3-981f-0800200c9a66',0,1);
and we will need to register our new alert so user will receive notification emails if selected in the Users -> Event Notifier tab:
insert into event_map(event_up_name, event_down_name) values('CLUSTER_ALERT_HA_RESERVATION', '');
Rest API
A small change to the Rest Api, adding a new property to the Cluster object to enable/disable the HA Reservation, named “ha_reservation” with valid values of true/false.
Backwards Compatibility
For this feature there are no changes in APIs to the host and all the logic will be done by the engine, there isn’t any backwards compatibility issues, the feature will be supported by all host versions.
Benefit to oVirt
Provide assurance to the end user that critical VMs will have access to the required resources in the event of a host failure without negatively impacting the collective performance of existing workloads