Most of them are outdated, but provide historical design context.
They are not user documentation and should not be treated as such.
Documentation is available here.
oVirt Scheduler
Summary
As oVirt is progressing and continue to gather features, there is an ever growing actual need for better scheduling: configurable, customized and flexible, both in the programmatic and functionality levels. It is known that the scheduling problem has NP-complete complexity, therefore there’s a need to optimize the problem solution, to do that each scheduler implementation should focus on it’s own subjective needs. To accomplish that we propose to have a scheduling API, in which the users can have their own private optimized schedulers by adding / modifying the default oVirt scheduler. This page includes the high-level design for the new scheduling model.
Owner
- Name: Gilad Chaplik (gchaplik)
- Name: Doron Fediuck (Doron)
- Email: dfediuck@redhat.com
Current status
Status: design
Last updated: ,
Benefit to oVirt
- Allow others to integrate with oVirt’s Scheduler.
- Allow users to add their own scheduling logic.
- Should allow other languages (Python), run as script/dynamically.
- Load balancing policies can be overwritten.
- Provides internal modularity and boundaries.
Description
oVirt Scheduler concepts
The new oVirt scheduler will use a process that gets a VM scheduling request, and will apply hard constraints and soft constraints to get the optimal host for that request at this point of time.
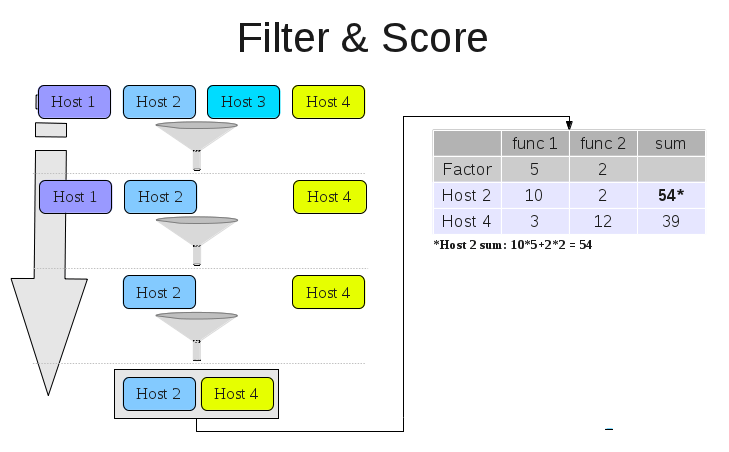
- Filter: a basic logic unit which filters out hypervisors who do not satisfy the hard constraints for placing a given VM.
- Cost function: a function that gives a score to a given host based on its internal logic. This is a way to implement soft constraints in the scheduling process.
- The scheduling process will take all relevant hosts and run them through the relevant filters
- Note that from one filter to another the host number may decrease
- Filter order is meaningless
- The filtered host list will then be used as an input to the relevant cost functions, which will create a cost table
- The cost table indicates the host with the lowest cost, which is the optimal solution for the given request.
- Cost function results may be prioritized using a factor.
Load Balancing
Load balancing logic is a separate logic functionality based on the balancing policy. The scheduler has a balance function that implements the policy. The internal load balancing policies oVirt scheduler supports, are based on VM migration. However, any user may implement a policy which balances the load base on taking a network-related action or even shutting down a physical server. So the key insight here, is that load balancing is a general term based on the load the user would like to handle. Another key insight is the fact that scheduling is strongly related to balancing. The reason is that we would like on going scheduling to work in synergy with the balancing policy. For example, there’s no point of placing a VM on a host we would like to shutdown to save power (power saving policy), as this will force the balancing logic to migrate this VM next time it runs. The way to express the balancing-scheduling relation is by correlating both in the following way: The balancing logic calculates over-utilized hosts based on the relevant policy. Then it can pick a VM to be migrated from each overloaded host. Additionally, the same balancing logic can calculate the under-utilized hosts. So once we know which VM(s) we want to migrate and where they should move to, the process will run the standard scheduling process, using the VM balancing wants to move and the under-utilized hosts. This is the only way to ensure we have no conflicts between scheduling and balancing. Finally, it is important to understand that balancing can be also expressed by filters and / or cost function. For example we can implement power saving policy by using a cost function that returns the number of VMs running on every host. This will give hosts running many VMs a higher grade which most likely to be used again. In this way every new VM will run on a host running other VMs, and every balancing iteration will migrate VMs to hosts running more VMs. The end result is a few hosts running most of the VMs and hosts running no VMs at all.
Using external code
The new design will be written in Java, but will allow users to add their own logic in Python. This will allow users to use the Python SDK for Filters, Functions and Balancing. In order to achieve that, the scheduling process needs to serialize parameters when calling the Python code. Past experience demonstrated this is a heavy load operation. So in order to reduce the number of serializations, the oVirt scheduler will have a Python proxy running the Python code, and the invocation to it will be done once for every request. So the expected flow is:
scheduling request -> Scheduler
-> Java Filtering process
-> Python Filtering process
-> Java cost process
-> Python cost process
<- Scheduling response
For safety reasons the proxy will run the external code in a safe way to may sure it does not crash if the external code crashes. It is expected that multiple Python logic will delay the scheduling process. So if performance needed, it’s adviced to add your logic in Java. Either way the scheduler will timeout if unable to satisfy a request in a given time period. So readers should be aware of the implications of slowing down the scheduling process.
Since internal filters and load balancers can run much faster, the engine will invoke all internal filters before any external filters.
Detailed Design
The specific API and design details can be found in the following page: Features/oVirtSchedulerAPI
References
Some of the concepts in this design are related to the filter scheduler Nova Scheduler is using. The idea is to possibly allow logic and potentially some code sharing between these sub-projects, even though both use different implementations and architectures.