Most of them are outdated, but provide historical design context.
They are not user documentation and should not be treated as such.
Documentation is available here.
Pass discard from guest to underlying storage
Summary
How thinly provisioned disks were previously used
Today, when the engine creates a thinly provisioned disk on a block domain, a logical volume with a preconfigured size is created, regardless its virtual size.
When the watermark comes near the LV’s size, the SPM extends the LV, so that the disk grows again and again until it reaches its virtual size.
If the lun that is used to create the storage domain is also thinly provisioned, it behaves in a similar way. That is, when the engine extends a disk with one Gigabyte, it doesn’t necessarily get 1G from the storage, but it does get 1G of virtual space. Therefore, like the LV, the underlying thinly provisioned lun will grow more and more until it reaches its virtual size.
Similarly, in file domains, the underlying thinly provisioned lun gets bigger as the corresponding disk’s file grows.
What could be improved
When files are removed from the disk by the guest, the LV does not shrink (it would if vdsm would have called lvreduce, but it can’t since vdsm is not aware of file removals in the guest). Since the LV’s size did not change, the thinly provisioned lun in the underlying storage did not change either.
So, in fact, although some of the disk’s space was freed, the underlying storage was not aware of it, practically creating a situation where the underlying thinly provisioned luns can only grow, and can never shrink.
The same goes with file storage - when files are removed by the guest, the disk’s actual size remains the same and so is the reported consumed space of the underlying thinly provisioned luns.
A better approach would be to “tell” the underlying storage that the guest freed some space that it doesn’t need anymore, so that someone else can use it.
For whom is this feature useful
This feature is useful for users that have thinly provisioned LUNs and wish to reclaim space released by their guests.
Owner
- Idan Shaby
- Email: ishaby@redhat.com
Current status
Released in oVirt 4.1.
General functionality and restrictions
Under the hood
This feature adds a new virtual machine’s disk property called “Pass Discard” (“Enable Discard” in the UI).
If all the restrictions are met and Pass Discard is enabled, when a discard command (UNMAP SCSI command) is sent from the guest, qemu will not ignore it and will pass it on to the underlying storage. Then, the storage will set the unused blocks as free so that others can use them, and the reported consumed space of the underlying thinly provisioned lun will reduce.
Possible consumers of the discarded blocks
Block storage
Since vdsm does not call lvreduce, the size of the LV is not reduced; only the reported consumed space of the lun in the underlying storage is reduced.
That means that if the guest frees some blocks from a disk that resides on a storage domain named sd1, other disks on sd1 will not be able to use it if sd1 went out of space.
To better understand what can and what cannot consume the new unused space, let’s take a look at the next example:
Suppose that we have a block storage domain named sd1 that is built on a thinly provisioned lun named lun1.
Also, suppose that we have two VMs, vm1 and vm2, with OSs installed and with thinly provisioned disks on sd1, disk1 and disk2, respectively (all the other restrictions are met).
Suppose that currently sd1 has 10G of free space, and that the virtual size of disk1 and disk2 is very big.
From lvm’s perspective - let’s say that vdsm created a pv pv1 out of lun1, and then created a vg vg1 from it (which is our storage domain, sd1). Our two disks, disk1 and disk2, are in fact simple logical volumes on vg1. Let’s assume that they are called lv1 and lv2, respectively.
Now, suppose that vm1 writes to disk1 10 more Gigabytes so that sd1 is out of space. Then, vm2 tries to write to disk2, the LV is already full and needs to be extended, but it fails because sd1 is out of space.
At first sight, it seems that if vm1 would have removed some files from disk1 and discarded the unused space, then lv2 could be extended and vm2 could write to disk2. But that’s not the case.
The reason for this is the implementation of lvm. When vm1 wrote 10G to disk1 and filled sd1 completely, lvm’s metadata indicated that vg1 was full, so that a logical volume in vg1 could not be given with additional logical extents anymore.
After vm1 discarded some unused blocks, lvm’s metadata didn’t change. That is, the size of lv1 was still the same, and so is the size of vg1 - it was still full. So when vdsm tried to extend lv2, it couldn’t, because there where no free logical extents in vg1.
As noted before, if vdsm frees some blocks from a disk that resides on a storage domain named sd1, other disks on sd1 will not be able to use it if sd1 went out of space.
So now we can better understand what can consume those discarded blocks:
- Disks on other storage domains - because the storage is not full; and if it was full - we’ve just discarded a few blocks that can now be consumed.
- Other disks on sd1 if sd1 is not out of space - because if the vg is not full, vdsm can extend its logical volumes with any blocks that it is given by the storage, and those discarded blocks are not exceptional.
- In fact, if sd1 went out of space, and enough blocks were discarded to extend it, the user can always do that by adding another lun to the domain or by extending the existing one using the Refresh LUN Size feature, making it possible for the logical volumes to extend.
File storage
Unlike block storage, file storage does not have restrictions caused by metadata, so if the underlying file system supports discard, it will work in any scenario.
If we take the example from above - after vm2 was unable to write to disk2, if vm1 removed some files and discarded the removed blocks from disk1, then:
- The actual size of disk1 reduces.
- The amount of free space in sd1 gets bigger.
- vm2 can write to disk2.
Restrictions
The underlying storage
Block storage
The underlying storage must support discard calls in order for this feature to work.
That’s why when trying to enable Pass Discard for a VM disk, the engine first queries the disk’s storage domain for its discard support.
To check if a storage device supports discard:
- Let lunX be a device and dm-X be its corresponding dm device for a natural number X. Then lunX is considered to support discard iff the value of
/sys/block/dm-X/queue/discard_max_bytesis bigger than 0 1. - A storage domain supports discard iff all of the luns that it is built from support discard. That means that if at least one of its luns doesn’t support discard, then so is the storage domain.
File storage
Since the shared file system adds another layer between the guest’s file system and the underlying shared block device, the engine can’t check if the block device supports discard. Therefore, Pass Discard can be enabled for any disk on any file storage domain, and it will actually work only if the underlying file system and block device support it.
Thus, Pass Discard on file storage works on the basis of best effort.
The virtual machine’s disk
It is possible to enable Pass Discard for two disk storage types: Images and Direct LUNs.
Regardless the type, the disk interfaces that support Pass Discard are VirtIO SCSI and IDE.
The guest virtual machine
Note
The following restrictions cannot be satisfied by the engine (at least not at this point, see the Future plans section for more details), and should be handled by the VM’s owner.
In order to send a discard command from the guest, one can do it:
- Manually - using the
fstrimlinux command. - Automatically on file removal (online discarding) - by adding the
discardoption to the list of the device’s mount options. For example, in EL based guests’/etc/fstab:
/dev/mapper/rhel-root / ext4 defaults,discard 1 1
# Here's the discard option -----------------^
For more information about sending discard from EL7 based OSs, refer to Storage Administration Guide - Discard unused blocks.
Either way, these conditions regarding the discard command should be met:
- It should be supported by the device’s file system, ext4 for example.
- It should be supported by the guest’s OS.
Wipe After Delete and Pass Discard
Block storage
When a disk’s Wipe After Delete property is enabled, the engine guarantees that when the user removes the disk, it would be first wiped and only then removed.
Since discarding a block in the storage means that it doesn’t belong to the LV anymore, and since vdsm cannot wipe this block before it is discarded by the guest, if a disk’s Wipe After Delete and Pass Discard properties were both enabled, some sensitive data could have been exposed as part of a new disk that could have been allocated with the same blocks to another user.
Thus, Wipe After Delete and Pass Discard cannot, theoretically, be both enabled for the same disk.
There is a case, though, where it’s possible. To understand it, let’s first take a look at these declarations:
- Let lunX be a device and dm-X be its corresponding dm device for a natural number X. Then lunX supports the property that discard zeroes the data iff the value of
/sys/block/dm-X/queue/discard_zeroes_datais 1 2. A lun that supports the property that discard zeroes the data guarantees that previously discarded blocks are read back as zeros from it. - A storage domain supports the property that discard zeroes the data iff all of the luns that it is built from support it. That means that if at least one of its luns doesn’t support the property that discard zeroes the data, then so is the storage domain.
Thus, Wipe After Delete and Pass Discard can be both enabled for the same disk iff the corresponding storage domain supports discard and the property that discard zeroes the data.
File storage
On file storage, the file system guarantees that previously removed blocks are read back as zeros. Thus, vdsm never wipes removed disks on file storage like it does in block storage, because the file system does the work for us.
Therefore, it is always allowed to enable both Wipe After Delete and Pass Discard for a disk on file storage, but such a disk cannot be moved to a block domain that doesn’t support both discard and the property that discard zeroes the data.
Usage
GUI
Note
The next screenshots were taken when the VM was down.
When the VM is up, Pass Discard cannot be edited.
Add/Edit a virtual machine’s disk
Disk image
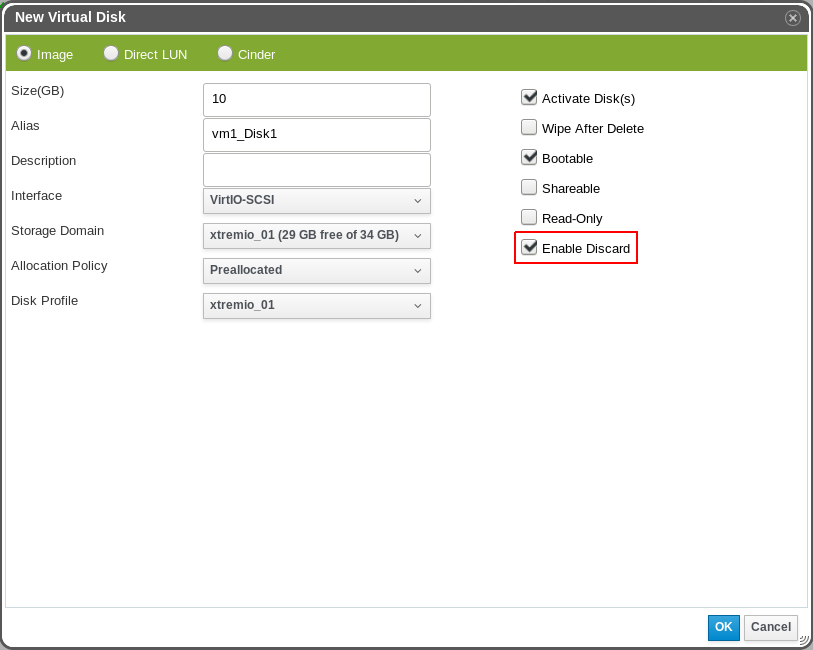
Direct LUN
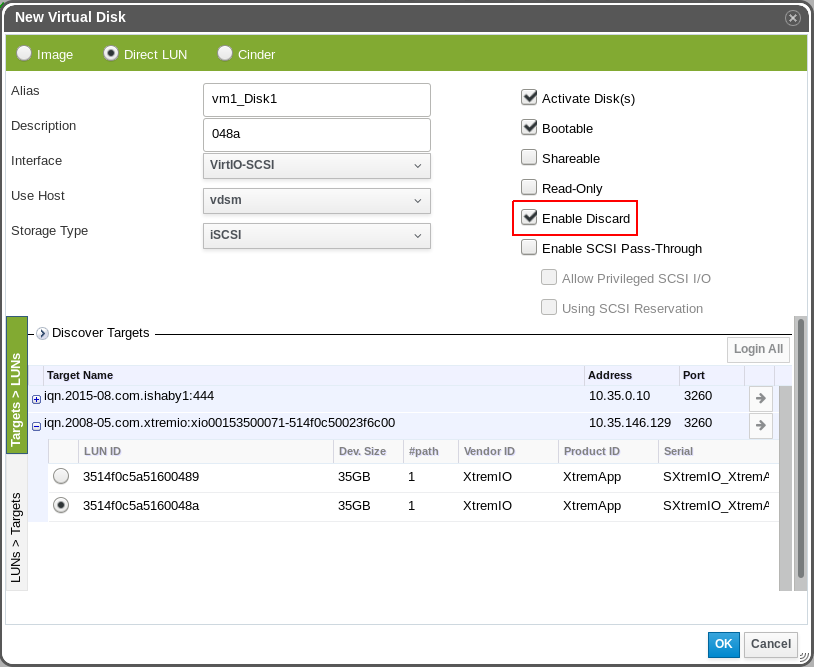
REST-API
Add a new virtual machine’s disk
POST api/vms/<vm_id>/diskattachments
Content-Type: application/xml
<disk_attachment>
<disk>
<alias>new_disk</alias>
<provisioned_size>1073741824</provisioned_size>
<format>cow</format>
<storage_domains>
<storage_domain id="<storage_domain_id>"/>
</storage_domains>
</disk>
<bootable>false</bootable>
<interface>virtio_scsi</interface>
<active>true</active>
<pass_discard>true</pass_discard> <!--The value of pass_discard -->
</disk_attachment>
Attach a disk to a virtual machine
POST api/vms/<vm_id>/diskattachments
Content-Type: application/xml
<disk_attachment>
<disk id="<disk_id>"/>
<bootable>false</bootable>
<interface>virtio_scsi</interface>
<active>true</active>
<pass_discard>true</pass_discard> <!--The value of pass_discard -->
</disk_attachment>
Update a virtual machine disk
PUT api/vms/<vm_id>/diskattachments/<disk_attachment_id>
Content-Type: application/xml
<disk_attachment>
<pass_discard>true</pass_discard> <!--The value of pass_discard -->
</disk_attachment>
Related Bugs
- Allow TRIM from within the guest to shrink thin-provisioned disks on iSCSI and FC storage domains(Bug 1241106)
Future plans
- It might be useful to add a possibility to configure the mount options of a VM disk for discard support from the engine.
- It’s worth checking if qemu/libvirt allow to update a disk’s driver when the VM is up. If they do, then Pass Discard can be edited also for a running VM.
Related Features
References
-
See “discard_max_bytes” in “Queue sysfs files” - https://www.kernel.org/doc/Documentation/block/queue-sysfs.txt ↩
-
See “discard_zeroes_data” in “Queue sysfs files” - https://www.kernel.org/doc/Documentation/block/queue-sysfs.txt ↩